The following screenshots of various pages within the database provide an overview of some of the site's capabilities.
NOTE: These screenshots represent earlier stages of database development and are now interesting mainly for historical purposes.
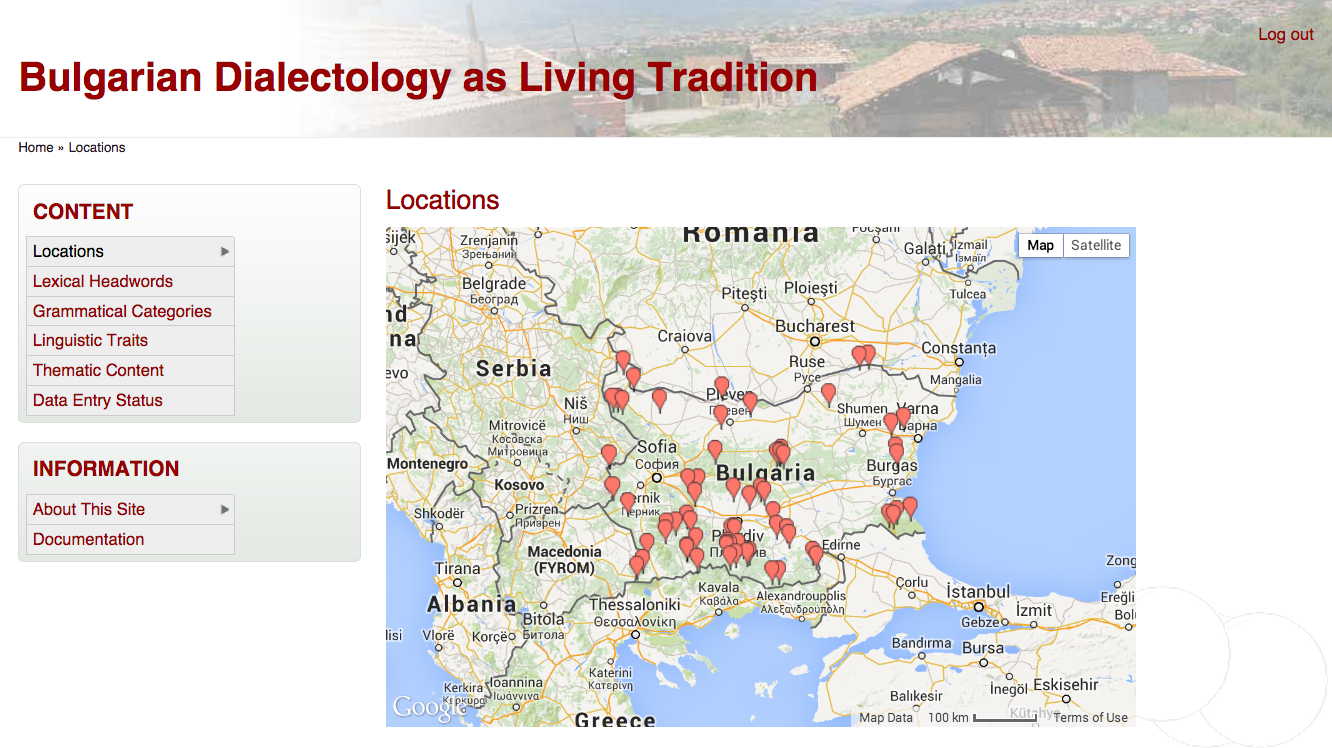
A navigable map displays at a glance the full coverage of the Bulgarian dialect area, and allows for easy access to texts from all locations in the database:
{kind=link}
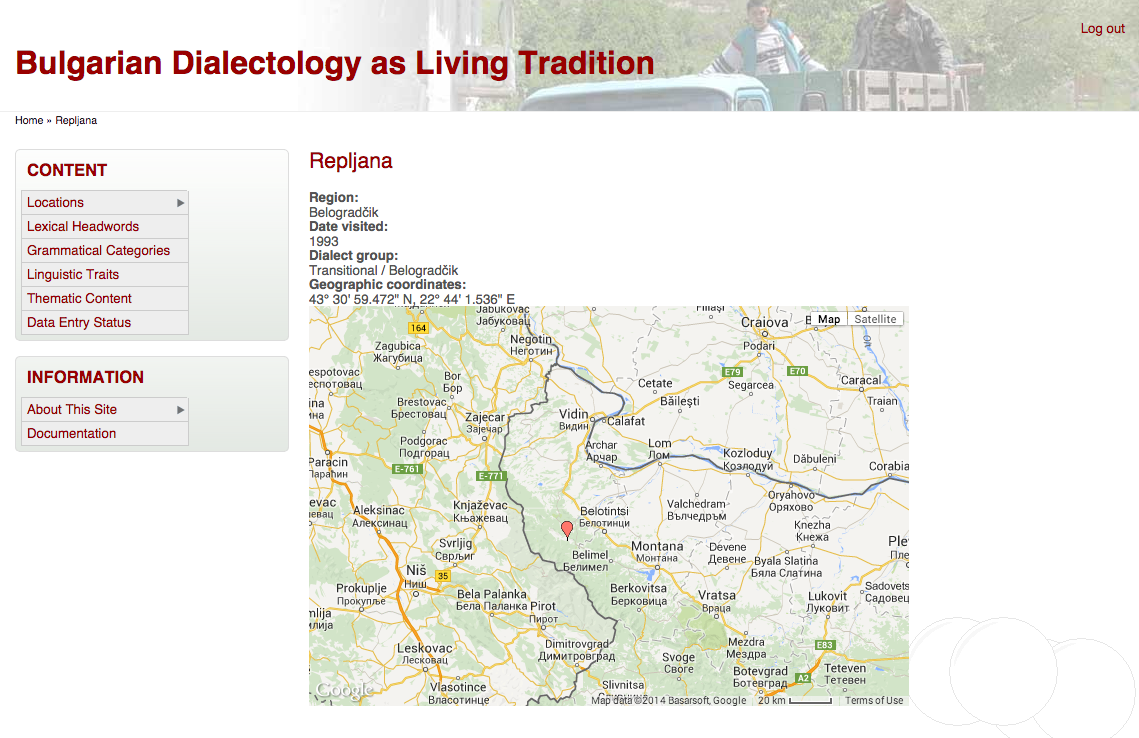
More information about the locations in which texts were recorded can be found on dedicated pages:
{kind=link}
Individual texts can be selected from a drop-down menu on the left of the screen:
{kind=link}
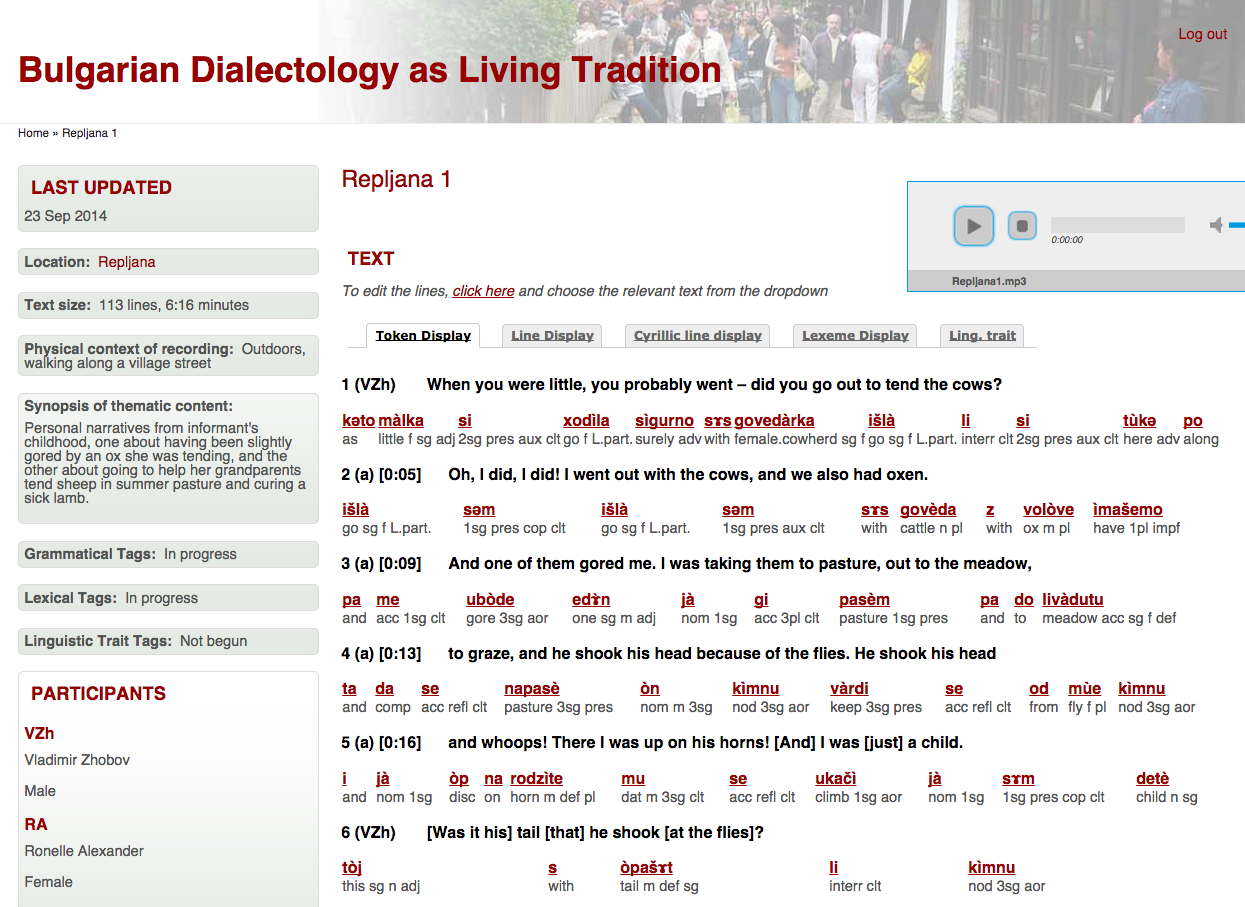
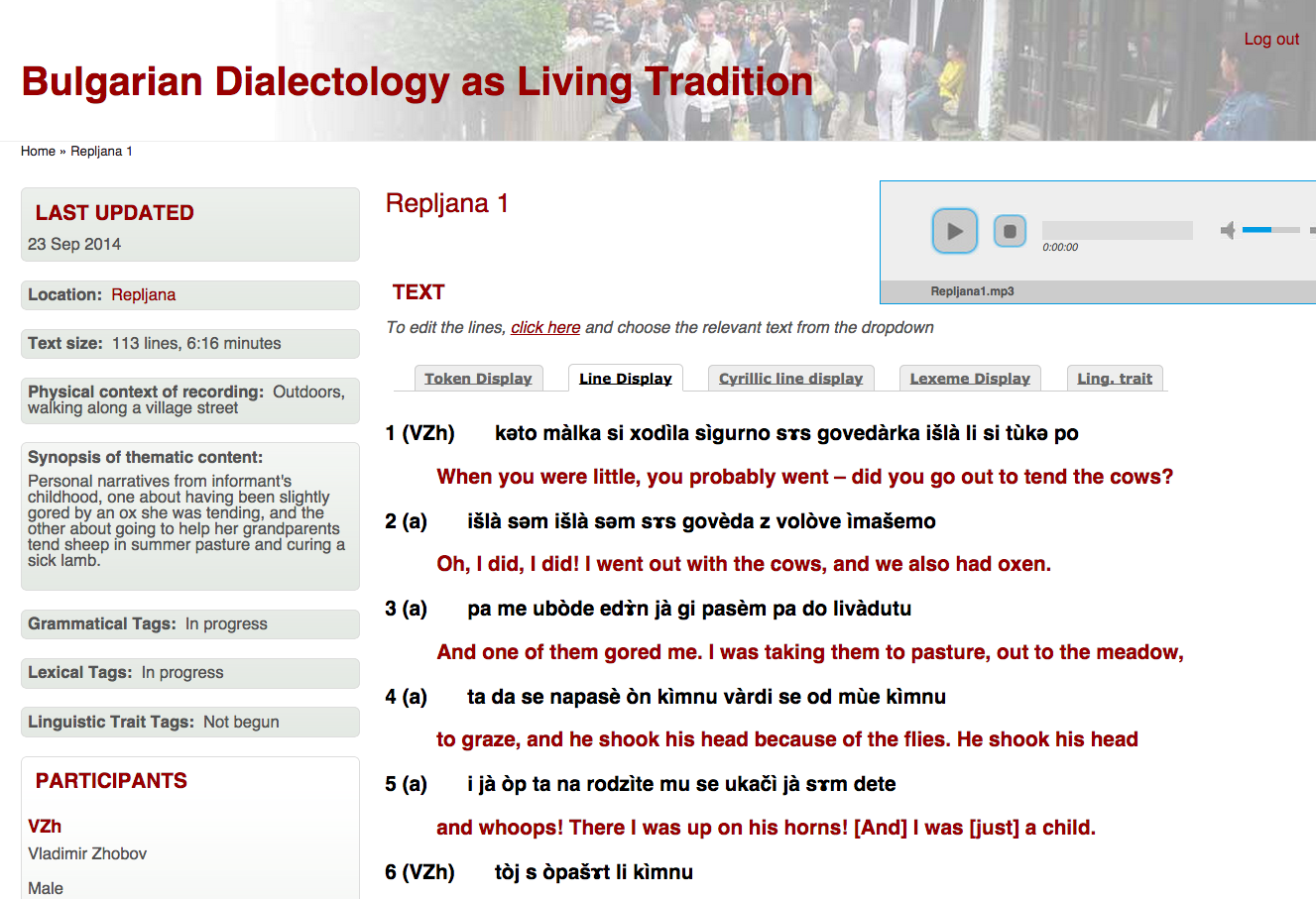
Texts can be viewed in a detailed Token Display, in a simplified Line Display, and in Cyrillic Line transcription, all with a floating bar for audio control:
{kind=link}
{kind=link}
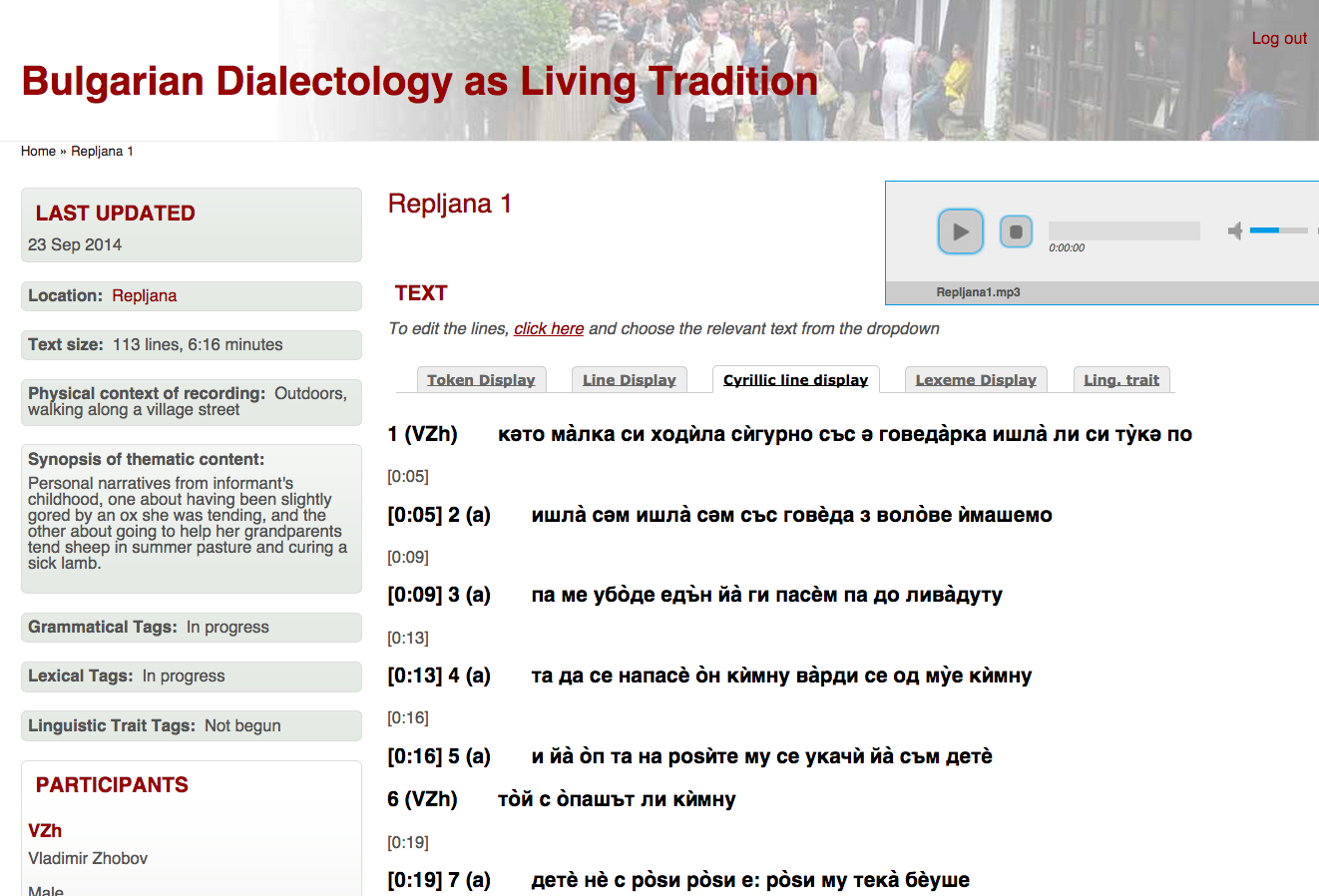{kind=link}
A simple search function allows for the identification of all tokens matching specific grammatical (or pragmatic) categories:
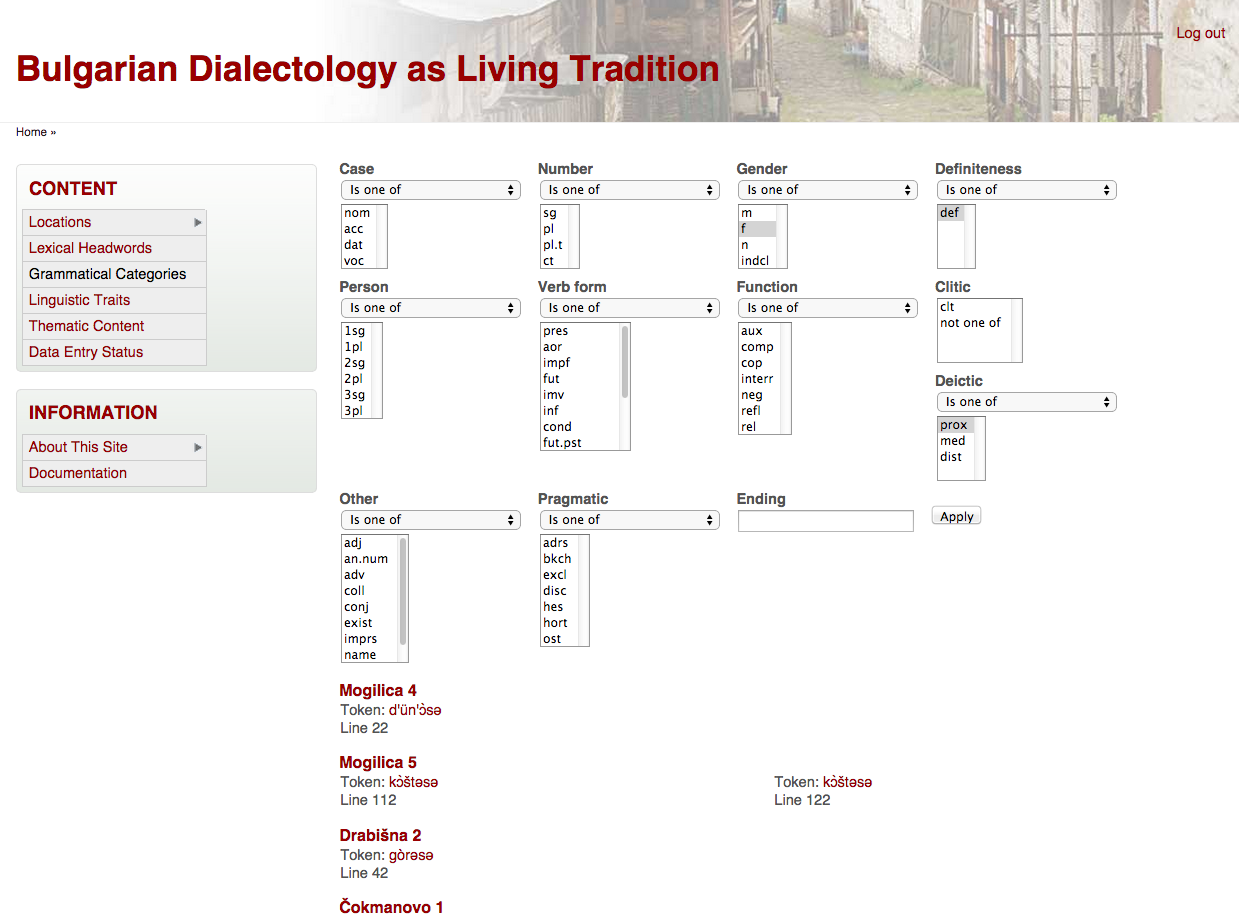{kind=link}
Users can locate all forms in the database derived from a given lemma (lexeme):
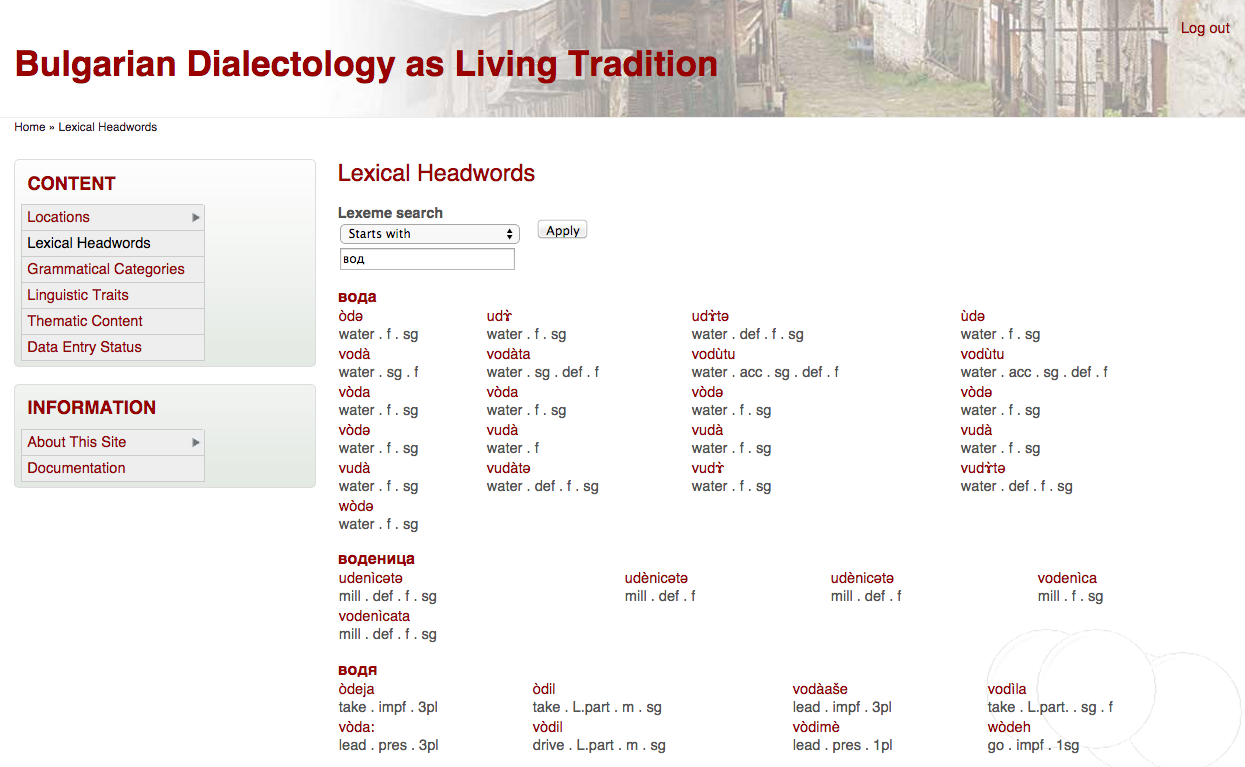{kind=link}
The presence of linguistic variables of interest to dialectologists, both simplex (such as definite article forms) and complex (such as reflexes of proto-Slavic vowels in specific environments) can be identified in tokens and displayed on a navigable map:
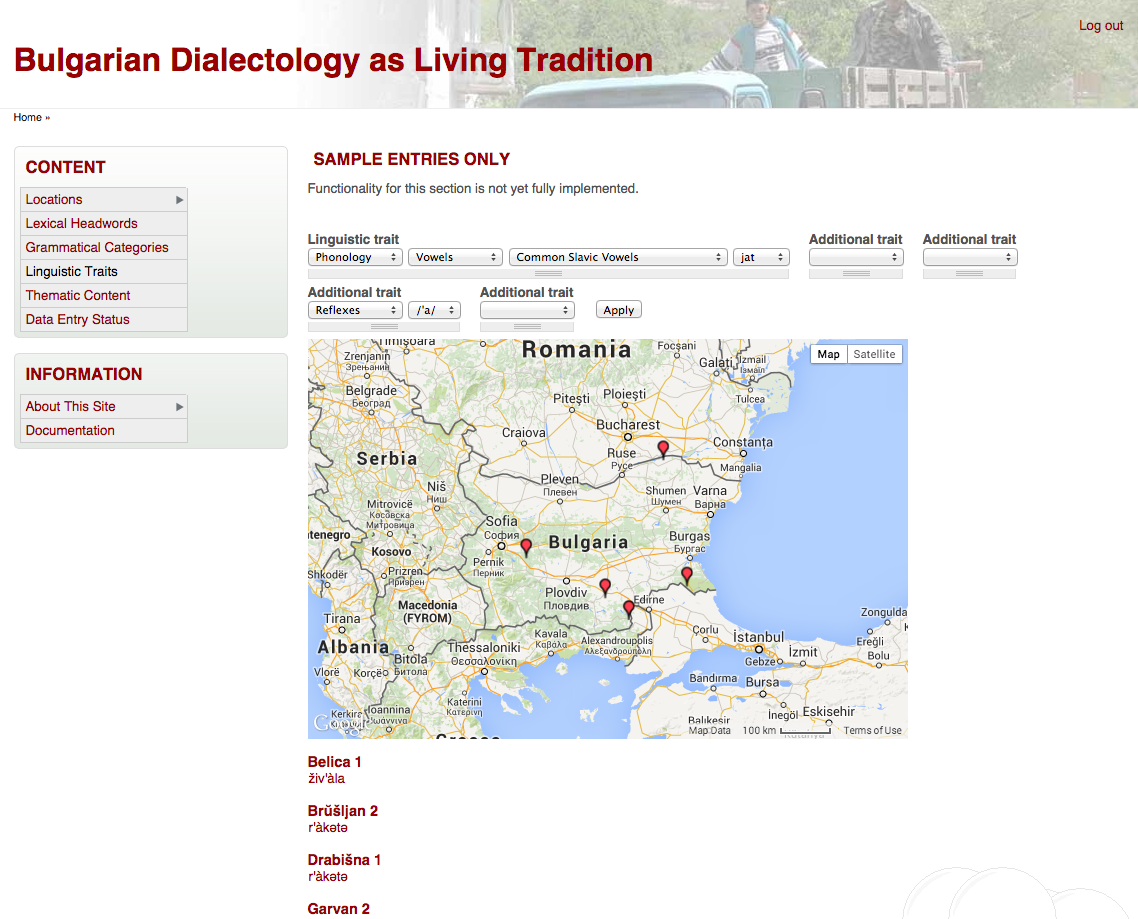{kind=link}